
If you’ve been following along with our Python for Digital Marketing posts, you’ve imported data from Google Analytics into a Jupyter Notebook and may have even combined it with another dataset. If you’ve never been here in your entire life but are starting at a large dataset, you’re probably still in the right place. So now that we have all this data, how can we break it down to learn more about specific parts of it? Enter the pandas groupby() function!
With groupby(), you can split up your data based on a column or multiple columns. You can then perform aggregate functions on the subsets of data, such as summing or averaging the data, if you choose.
In this article, we’ll cover:
- Grouping your data
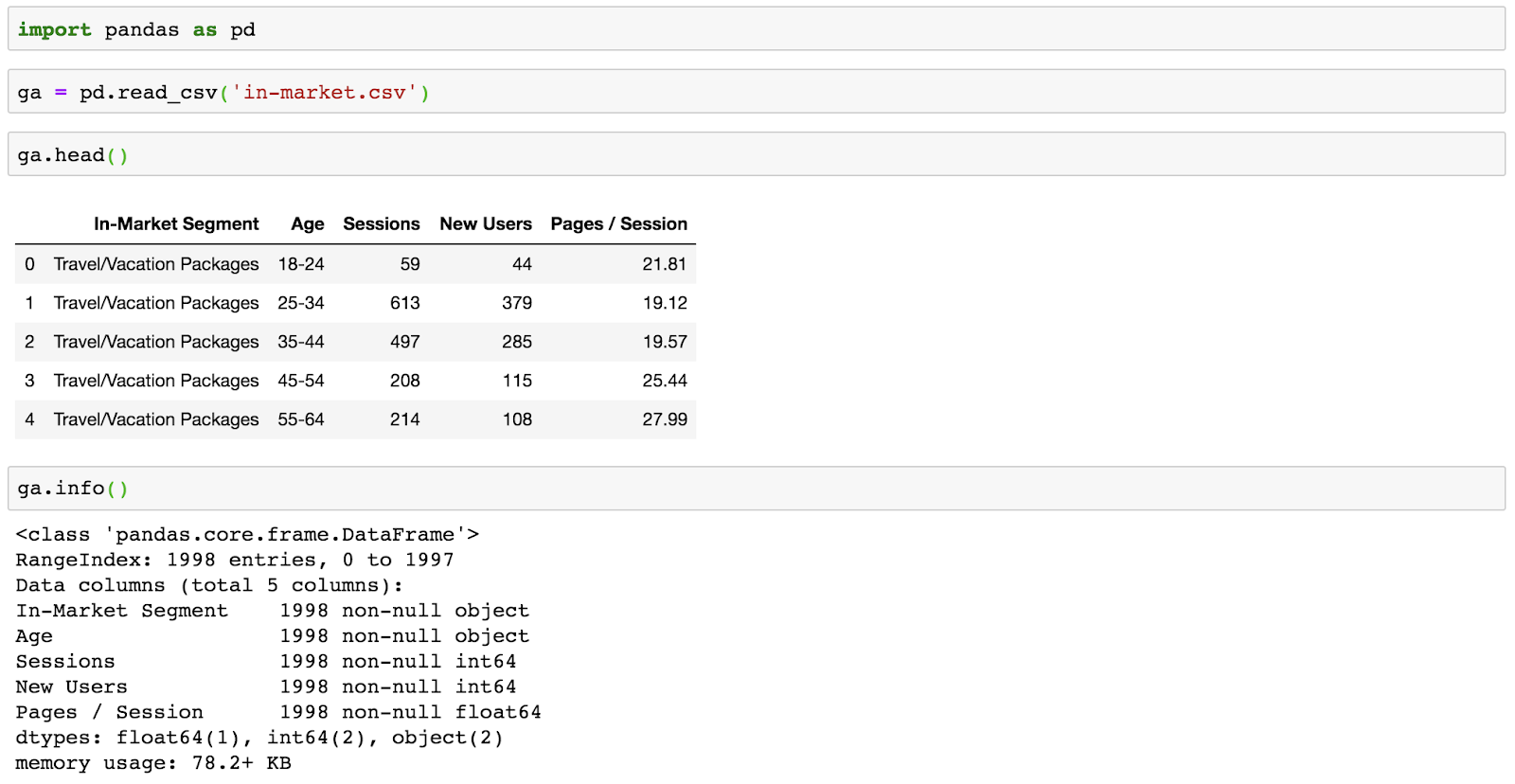
For this example, I’m using in-market audience data paired with age groups from Google Analytics.
As always, I’ll start by importing pandas, reading in my CSV, and checking out the head()and info()on the DataFrame.
Grouping Your Data
This step basically sets you up to perform the aggregate functions on your data. With your end goal in mind, decide if you need to group based on one column or multiple.
Group By One Column
To group your data by a single column, pass the column name into the groupby() function. In this example, I’ll group by the Age column:
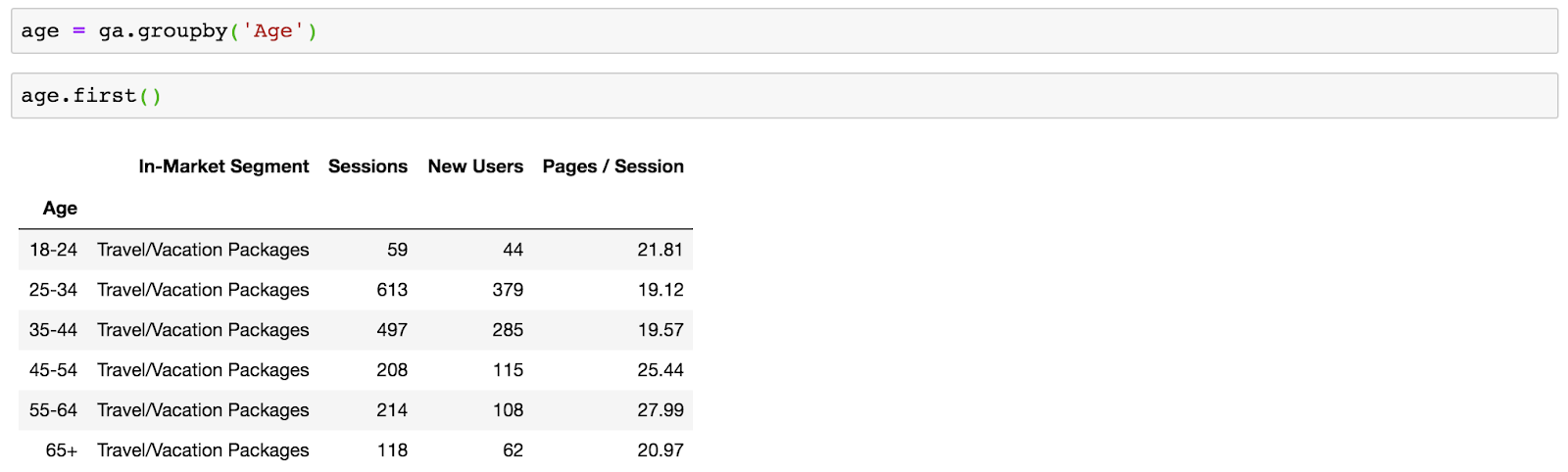
Using first(), I can see the first entry in each of my age groups.
Group By Multiple Columns
Instead of just grouping my data by Age or In-Market Segment, I may want to create subsets based on both. All I need to do is pass both of these column names into the groupby() function:
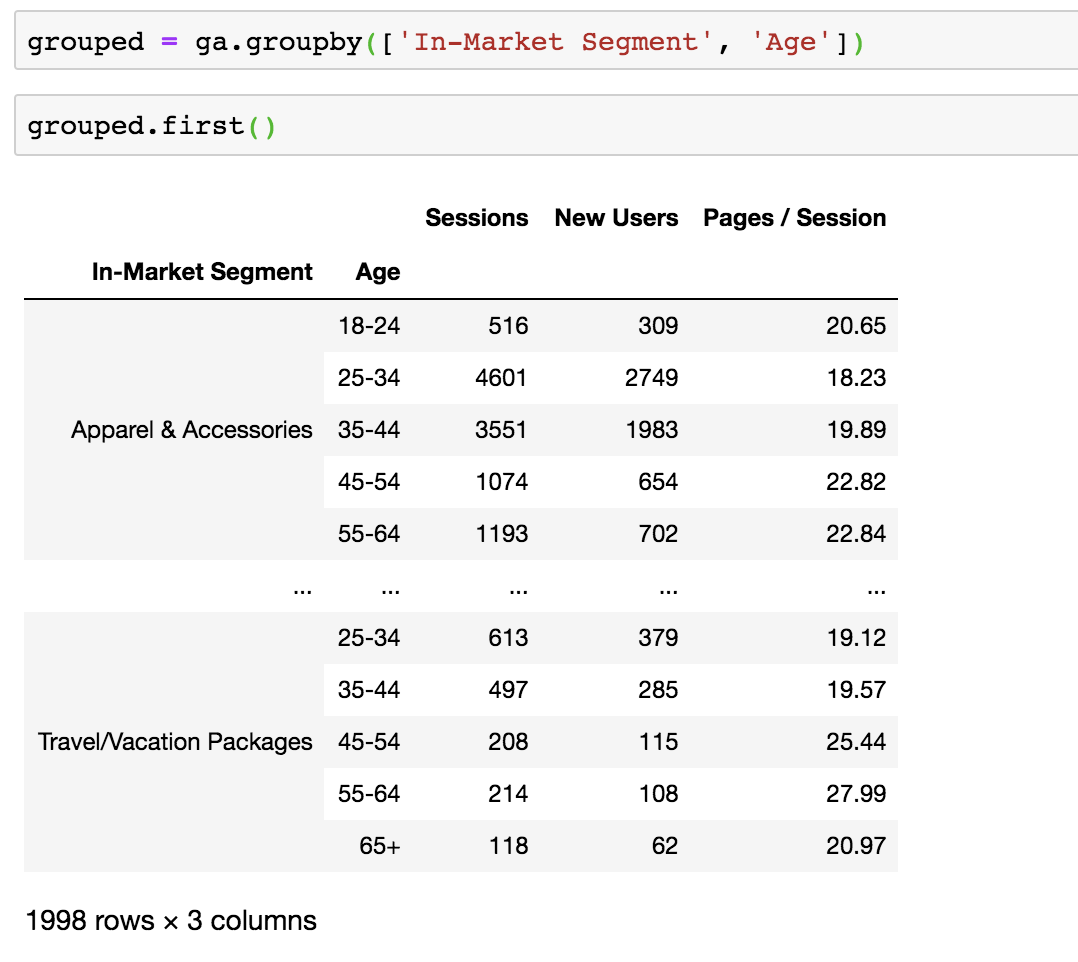
This creates a really nice looking output that shows that data from each age group within an in-market segment.
View Data From a Group
If I want to look at the data from one of my Age groups, I can do so with get_group(). Here I’m looking at all of the values from my 25-34 group:
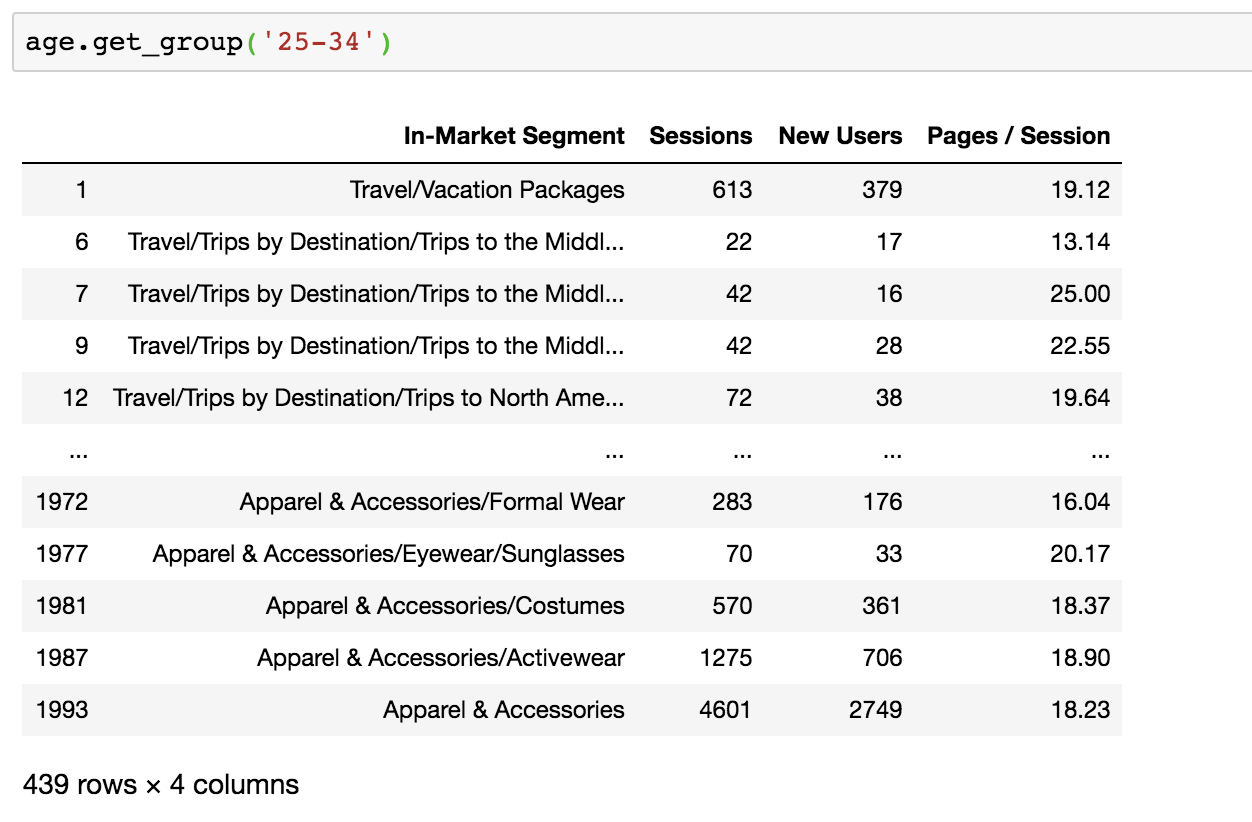
To do this with a DataFrame that was grouped based on multiple columns, pass values for each column into the get_group() function as a tuple:
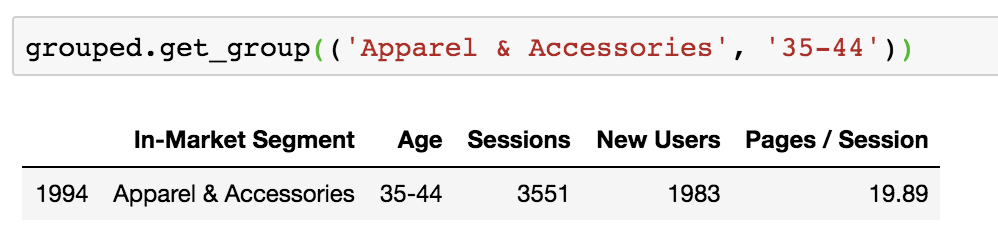
Apply Aggregate Functions
Okay, on to the good stuff! We’re going to apply some aggregate functions to our newly formed groups.
*Note: If your numerical values contain commas or percentages, they will read in as objects and you’ll get an error when trying to perform aggregate functions. You’ll need to clean up your data before this step so they are datatypes that you can work with, like integers or floats.
Apply an Aggregate Function Across All Columns
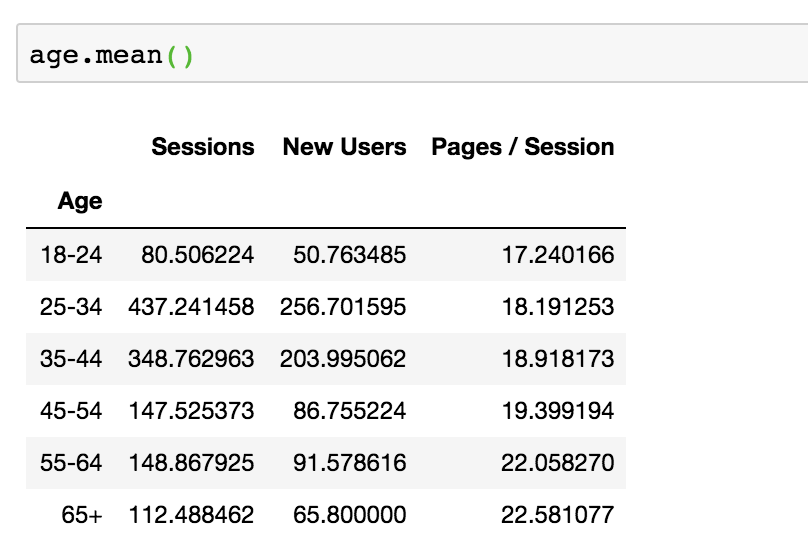
An aggregate function can be applied across all columns by simply adding the function to the DataFrame:
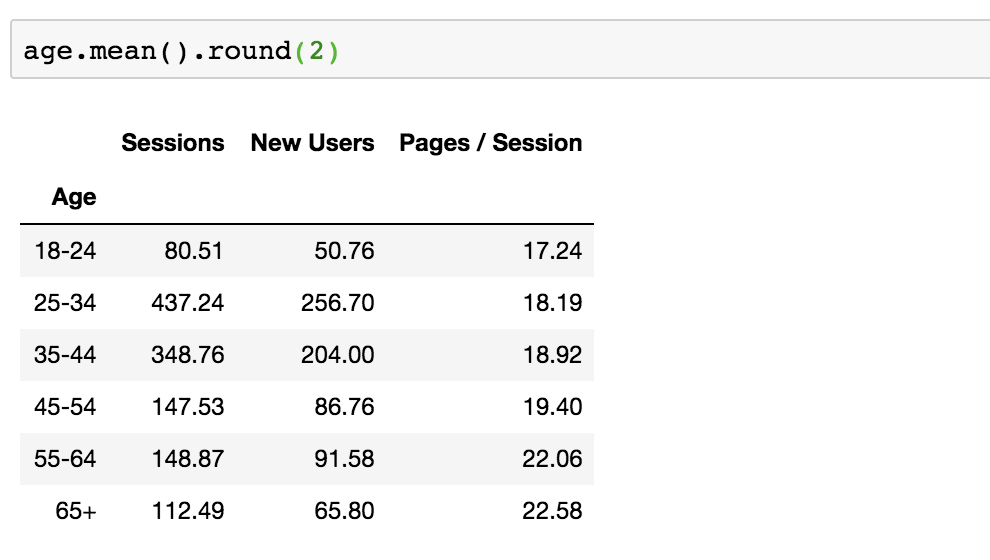
This can be cleaned up a little more by rounding the values to a decimal place that you choose. Here I’m rounding to the nearest hundredth.
Other functions you may want to use like mean(), max(), min(), std(), or count() can be applied in the same way.
Apply Aggregate Functions Based on Columns
Sometimes it won’t make sense to apply the same function across all of your columns. If I wanted to use sum() for example, the output for the Pages / Sessions column won’t make sense since it’s an average. I have two options in scenarios like this.
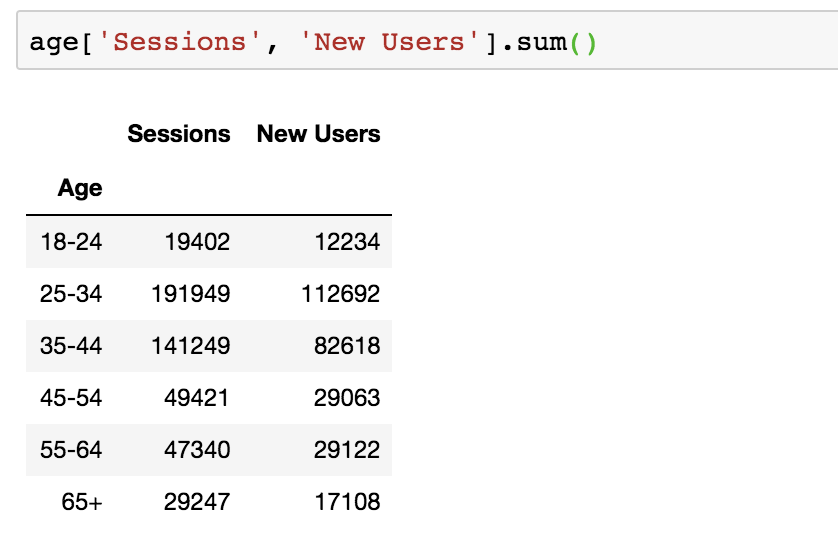
Option #1: Apply the function to certain columns.
Here, I’m passing in the columns that I want to sum up, which completely leaves the Pages / Session column out.
Option #2: Specify the function that should be used for each column.
Using a dictionary, we can identify which function should be applied to each column.
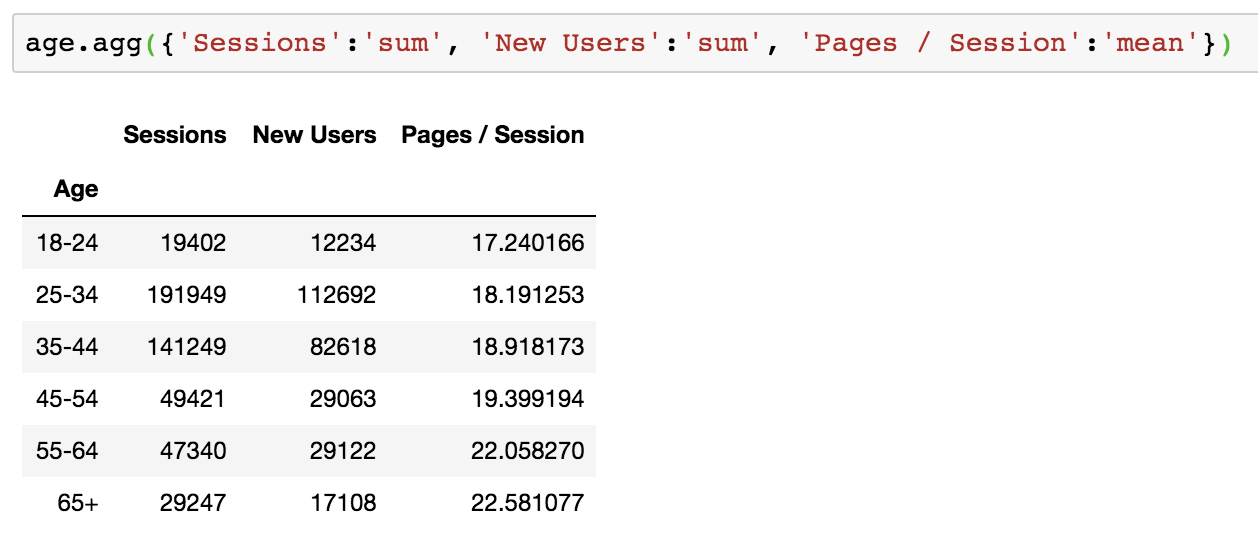
Apply an Aggregate Function To a Single Group
I can also drill down to a single group. If I want to look at the average number of sessions from 45-54 year olds in the Travel/Vacation Packages segment, I can do so with the following:
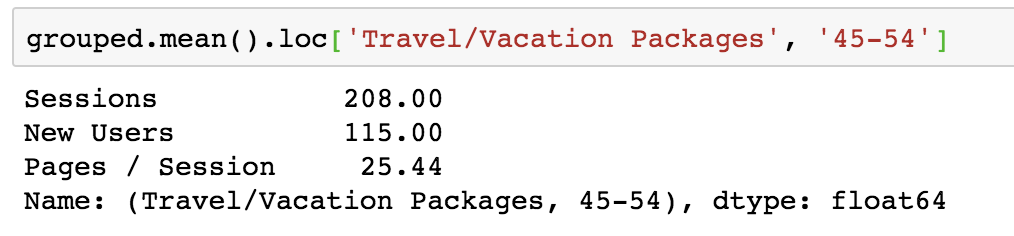
This gives me the average for each metric in this group.
As you can see, groupby() is a simple but powerful tool in the pandas toolbox. I hope it helps you extract more meaning out of your datasets and saves you from some manual work. Keep calm and group on!
The post Pandas Groupby Function: Python for Digital Marketing appeared first on Cypress North.